Multi-Agent Research
A complex research agent that can search the web and spin up multiple independent research sub-agents.
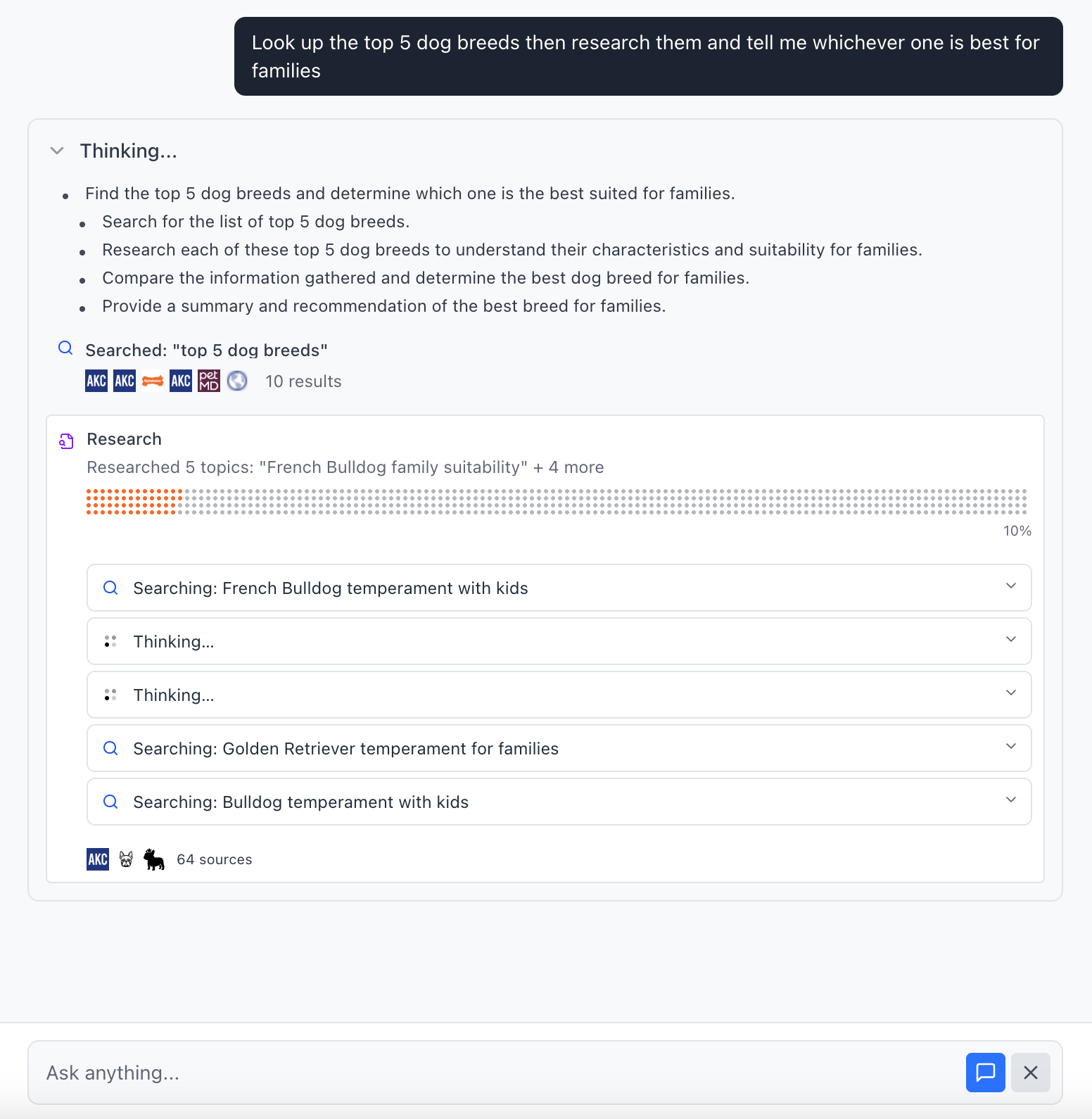
1. Create the agent
agent.py
import os
from dotenv import load_dotenv
from factorial import Agent, AgentContext, gpt_41
from exa_py import Exa
load_dotenv()
exa = Exa(api_key=os.getenv("EXA_API_KEY"))
def search(query: str) -> tuple[str, list[dict[str, Any]]]:
"""Search the web for information"""
result = exa.search_and_contents(
query=query, num_results=10, text={"max_characters": 500}
)
data = [
{"title": r.title, "url": r.url}
for r in result.results
]
return str(result), data
basic_agent = Agent(
instructions="You are a helpful assistant. Always start by making a plan.",
tools=[search],
model=gpt_41,
)
The agent now has the ability to search the web.
2. Register the runner
orchestrator.py
from factorial import Orchestrator, AgentWorkerConfig
from agent import basic_agent
orchestrator = Orchestrator(openai_api_key=os.getenv("OPENAI_API_KEY"))
orchestrator.register_runner(
agent=basic_agent,
agent_worker_config=AgentWorkerConfig(workers=50, turn_timeout=120),
)
if __name__ == "__main__":
orchestrator.run()
register_runner spins up a pool of workers that pull tasks from Redis and drive the agent.
3. Forking tools: spawn independent child tasks
Let's say we want to give our agent the ability to spin up multiple independent research subagents and wait for their results. We can do so by creating a new tool that spawns multiple child tasks using the @forking_tool.
First, create the research subagent:
from factorial import BaseModel
class SubAgentOutput(BaseModel):
findings: list[str]
search_agent = Agent(
name="research_subagent",
description="Research Sub-Agent",
model=gpt_41_mini,
instructions="You are an intelligent research assistant.",
tools=[plan, reflect, search],
output_type=SubAgentOutput,
)
Register the subagent's runner in your orchestrator:
orchestrator.register_runner(
agent=search_agent,
agent_worker_config=AgentWorkerConfig(workers=25, turn_timeout=120),
)
Now create the forking tool that spawns child tasks:
from factorial.tools import forking_tool
from factorial.context import ExecutionContext
@forking_tool(timeout=600)
async def research(
queries: list[str],
agent_ctx: AgentContext,
execution_ctx: ExecutionContext,
) -> list[str]:
"""Spawn child search tasks for each query."""
# Create payloads for each child task
payloads = [AgentContext(query=q) for q in queries]
# Spawn child tasks and get their IDs
child_ids = await execution_ctx.spawn_child_tasks(search_agent, payloads)
return child_ids
Key points:
@forking_tool(timeout=600)marks the tool as one that spawns child tasks- The tool MUST return the list of the child task ids for the parent agent to wait and listen for their completion.
- The parent task pauses until all child tasks complete
- Child results get automatically formatted and added to the conversation
When the agent calls this tool, it:
- Creates child tasks for each query
- Returns the child task IDs
- Pauses execution of the parent agent
- Resumes when all children complete, with results in the conversation
4. Expose an API & WebSocket
server.py
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from fastapi.exceptions import HTTPException
from pydantic import BaseModel
import json
from starlette.websockets import WebSocket, WebSocketDisconnect
from agent import basic_agent
from orchestrator import orchestrator
app = FastAPI()
@app.websocket("/ws/{user_id}")
async def websocket_updates(websocket: WebSocket, user_id: str):
await websocket.accept()
try:
async for update in orchestrator.subscribe_to_updates(owner_id=user_id):
await websocket.send_text(json.dumps(update))
except WebSocketDisconnect:
print(f"WebSocket disconnected for user_id={user_id}")
class EnqueueRequest(BaseModel):
user_id: str
message_history: list[dict[str, str]]
query: str
@app.post("/api/enqueue")
async def enqueue(request: EnqueueRequest):
task = basic_agent.create_task(
owner_id=request.user_id,
payload=AgentContext(
messages=request.message_history,
query=request.query,
),
)
await orchestrator.enqueue_task(agent=basic_agent, task=task)
return {"task_id": task.id}
class SteerRequest(BaseModel):
user_id: str
task_id: str
messages: list[dict[str, str]]
@app.post("/api/steer")
async def steer_task_endpoint(request: SteerRequest):
try:
await orchestrator.steer_task(
task_id=request.task_id,
messages=request.messages,
)
return {
"success": True,
"message": f"Steering messages sent for task {request.task_id}",
}
except Exception as e:
return {"success": False, "error": str(e)}
class CancelRequest(BaseModel):
user_id: str
task_id: str
@app.post("/api/cancel")
async def cancel_task_endpoint(request: CancelRequest):
try:
await orchestrator.cancel_task(task_id=request.task_id)
return {
"success": True,
"message": f"Task {request.task_id} marked for cancellation",
}
except Exception as e:
return {"success": False, "error": str(e)}
5. Queue your first task
curl -X POST http://localhost:8000/api/enqueue \
-H "Content-Type: application/json" \
-d '{
"user_id":"demo",
"message_history":[],
"query":"What is the capital of France?"
}'
The response contains the task_id. Open the WebSocket at ws://localhost:8000/ws/demo to watch progress in real-time.
6. Steering & cancellation
# append a follow-up instruction
curl -X POST http://localhost:8000/api/steer \
-d '{"user_id":"demo","task_id":"<id>","messages":[{"role":"user","content":"make it short"}]}'
# stop the task
curl -X POST http://localhost:8000/api/cancel \
-d '{"user_id":"demo","task_id":"<id>"}'
steer publishes run_steering_applied / run_steering_failed events.
cancel publishes run_cancelled.
7. Run everything
# run orchestrator
python orchestrator.py
# run api
python server.py